
Сегодня мы научимся как распознать текст из фотографии или документа PDF через онлайн сервис :OCR:. Также рассмотрим различные варианты вывода текста из изображения напрямую в формат WORD, EXCEL и обычный текст, и определим какой из этих типов документов будет оптимальным.
Допустим, у вас есть файл в формате PDF и его нужно преобразовать в текстовые данные. Как это сделать?

Переходим в редактор OCR, далее выбираем язык текста для распознавания и, конечно же, загружаем сам файл PDF.
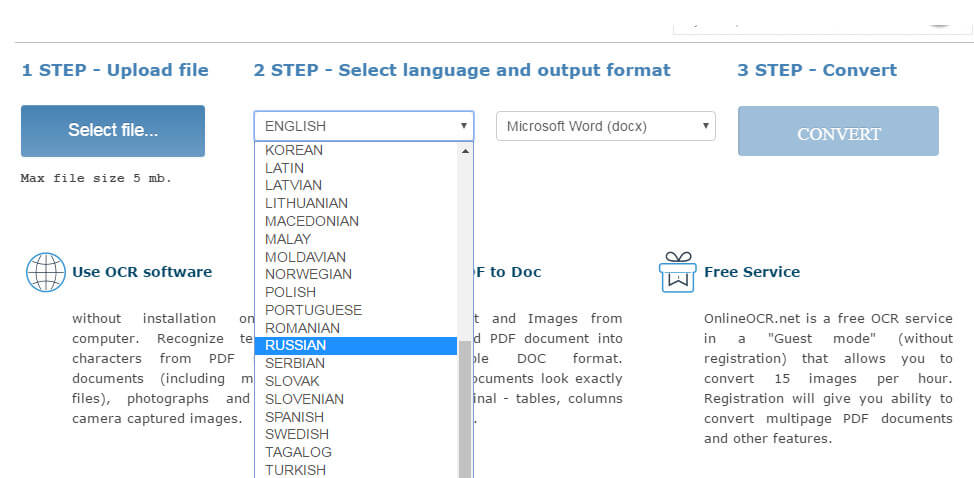
Далее выбираем из выпадающего списка нужный формат для конечной обработки. Среди них есть такие варианты: .DOCX, XSLX,.TXT.

Теперь вводим капчу, начнется загрузка нашего файла... ждем ее окончания.
Вам предлагается по окончанию загрузки и конвертации файла либо загрузить в доступном формате, который вы выбирали ранее из выпадающего списка, либо скопировать данные с текстом напрямую в окошке.
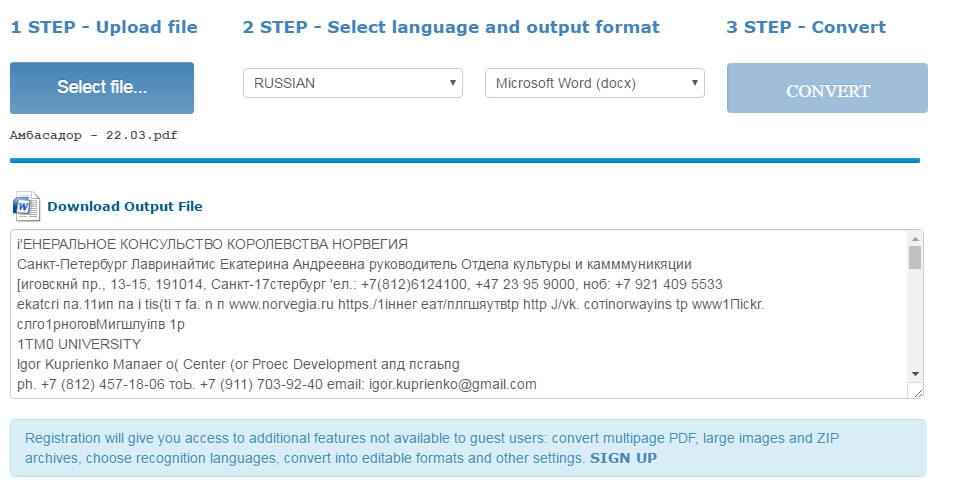
Примерно так выглядит текст в Word после расшифровки:
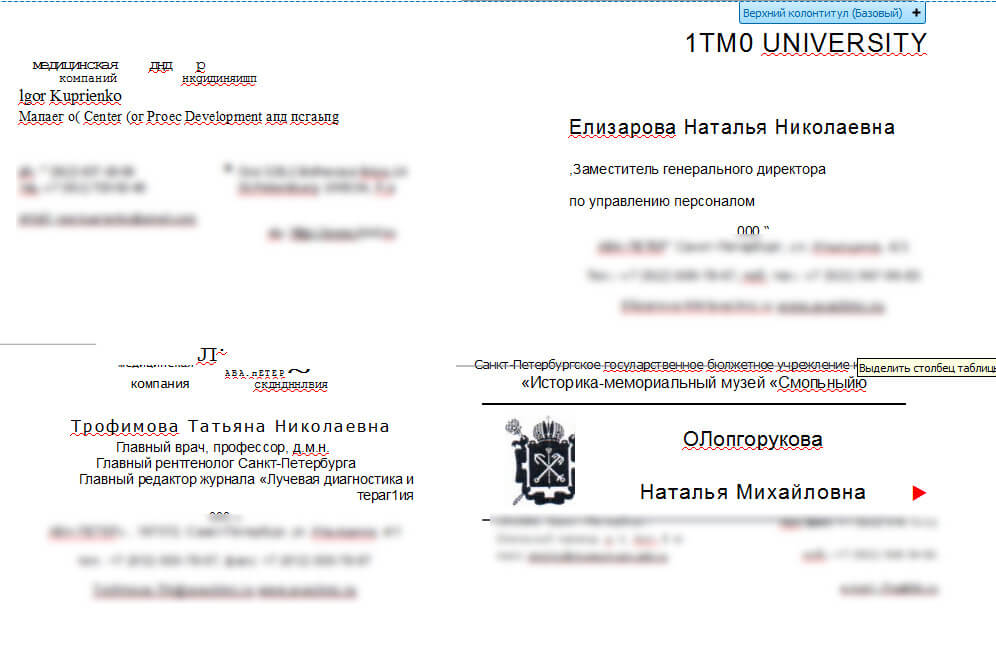
Что будет, если попытаться снова загрузить PDF и получить обычный текст?
Вот так выглядит конечный результат:
Или в последнем варианте обработки - файл Excel:
Итоги
В целом онлайн сервис по расшифровке текста работает хорошо, если учесть что он бесплатный. Но в то же время, есть и более продвинутые решения, хотя они - платные. Есть выбор!
Нажмите для реакции


